










解锁更多数据标注类型 百度数据众包支持清华大学十亿像素视频数据集
近日,百度智能云数据众包与清华大学开展项目合作,推进全球首个十亿像素级视频数据集PANDA的建设工作,用以支持未来在公共安全、智慧城市、虚拟现实等领域的各项研究及应用。

本次项目共完成7200余帧亿级像素图片,共计超过106万张切图的数据标注工作,包括物体间关系近2万组、交互行为近20万个、移动物体轨迹点近30万组,以及数十亿3D点云数据的语义分割及实例标注,极大地丰富了PANDA现有数据集,并为清华大学后续举办的GigaVision(十亿像素级机器视觉)主题挑战赛提供数据支持。

同一人物动态切图
(图源:清华大学GigaVision挑战赛PANDA数据集视频演示)
近年来,行人检测、轨迹跟踪、动作识别、异常检测、属性识别等计算机视觉分析,已广泛运用到无人驾驶、智能安防、智慧城市等多个领域。AI算法应用的背后,离不开大批量、高质量的标注数据。百度数据众包作为国内最大的AI数据服务提供商,具备数据“采、标、存、管、训”一体化的服务能力,专注于为人工智能的发展与应用赋能。
据了解,PANDA是全球首个十亿像素级视频数据平台,它突破了人眼视觉分辨率的极限,赋予视觉计算更高质、更真实、更全面的源数据,填补了国际上“宽视场、多对象、高分辨率”数据平台的空白,为新一代智能处理技术研究提供了不可或缺的数据基础。
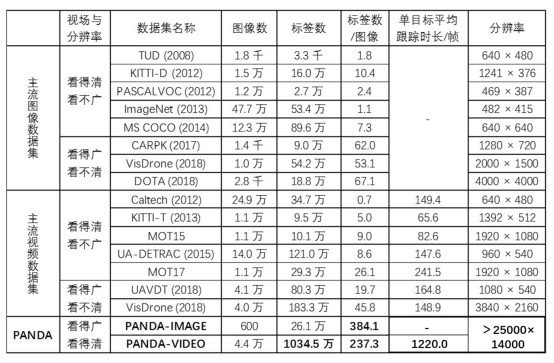
主流图像及视频数据集对比

清华大学电子工程系副教授、PANDA数据集项目负责人方璐介绍,此前清华大学团队曾围绕PANDA数据集,在计算机视觉顶级国际会议ECCV 2020上,组织了GigaVision 2020挑战赛并引起广泛关注。目前,团队正在筹办ACMMM2021会议的GigaVision主题挑战赛,以及全球人工智能技术创新大赛的相关赛道。
研究现实世界中大规模人群的复杂行为及交互方式,对于人工智能系统更好地理解人的行为与意图,进而提升智能决策能力有着重要意义。PANDA数据平台的构建,使得对于大场景、多对象、复杂关系的建模与分析成为可能。未来,百度将持续与清华大学合作,以技术赋能,推进PANDA数据平台的建设与发展。
百度作为国内人工智能领军企业,也是中国唯一在智能交互、智能基础设施和产业智能化领域,都形成了优势的AI平台型公司。依托百度多年AI数据经验,百度数据众包专注以数据智能对外赋能,致力于提供优质数据服务,携手政府、企业、高校等更多合作伙伴,共同推进新一代人工智能的高质量发展。

