







号外!号外!仅需5000元,即可配置Apollo计算平台!
在过去几个月中,Apollo代码达到了每周数十次的更新频率,新增代码数量共计可以达16.5万行。
如今近8000个开发者投票支持Apollo开源软件,超过1800个合作伙伴使用Apollo开源代码,100多个合作伙伴申请开放数据。

了解到这些,作为百度Apollo开发者阵营中的一员,也是一个30年资深的“金领码农”,老黄坐不住了,本着对自动驾驶的热忱以及对百度Apollo平台的兴趣,做了一件“惊天动地”的事儿!
对了,先介绍下我们文章的主人公老黄吧!
老黄,本名黄英君,1991年就读国防科技大学,系统工程与数学系、多媒体与虚拟现实专业方向博士,师从吴玲达教授。
毕业留校工作,在管理科学与工程学院从事视频分析与编解码、机器视觉、智能硬件方面的研究工作。
2012年转业,工作于中科院软件所广州分所,任商业智能实验室主任,从事电商平台与大数据分析方面的研究与软件开发工作。
2017年9月,加盟长沙智能驾驶研究院,任产品研发部门负责人,从事智能驾驶方面解决方案与产品的开发工作。

老黄究竟做了一件什么事儿呢?
老黄利用Apollo提供的各种资源与能力,自研成功解决了TX2嵌入式计算平台(NVIDIA JETSON TX2)适配Docker的尝试,简单来说就是使用低成本方案搭建部署了Apollo环境,值得注意的是此前官方并没有发布相关部署的指导文件……
最最重要的一点,细心的老黄不但完成了技术尝试,还将整体的过程做了完备的记录,总结了一份环境搭建攻略并分享出来。说到这里,小编也不禁为老黄这位开发者无私分享的行为疯狂打call!
是什么原因让老黄做了这么一件有意义的事情?
谈及原因,老黄很实在。
一方面是因为公司有需求,想通过一辆林肯mkz实验自动驾驶算法方面的研发水平。
还有一个特殊根源在于,公司预定了英伟达AI超算平台的高端产品PX2做一些产品规划,但货品迟迟未到,老黄想着同样是该系列的产品,或许TX2会有更多的惊喜发现。
最重要的一点,像老黄一样的开发者一直觉得,自动驾驶研发的目的不是取代人,而是应该走向普通人的生活,用来提升驾驶乐趣,如果开发成本很高,就很难体现其中的价值。
他对小编说:“如果用看似很低端的设备,用极低的成本实现自动驾驶的某些功能,那就是一件特漂亮的事情,所以我就大胆的做了这个!”
其实,老黄作为自动驾驶领域的开发者,在百度Apollo出现之前,一直关注Autoware**(城市自主驾驶的开源软件)**的源码,也就是日本名古屋大学的那款。他自己觉得,从最初的感觉来看,Autoware更像一个完整的解决方案,东西很全……Apollo生态出现后,觉得很有兴趣,很有实操感,瞬间转成“真爱粉”,这也是尝试的原因所在。
选择NVIDIA TX2,老黄前后思索了很久…
老黄可以称之为资深程序员,漫长的职业生涯中专攻软件整体架构和性能优化,尤其关注软件的总体构建方案、软件与硬件的整合以及算法的优化等方面,对很多市面上的算法平台都研究过。
说到选择NVIDIA TX2,老黄还有点儿感慨,“现在做平台的太多了,如恩智浦的BlueBox,再就是NVIDIA的TX&PX系列,还分了很多流派,什么NVIDIA、英特尔……可是大多数都还没有完全推出市场,成熟度也不算很高,这是比较头疼的事情。NVIDIA这个品牌吧,产品布局早,成品本身技术属性也很强大,像TX2,6核CPU,256个GPU单位,功耗15瓦,本身小巧轻便,集成度很赞,天然适合放在汽车这个环境里做研发!”

NVIDIA TX2
说到这一点,小编也觉得,如果封装超算平台的盒子占据汽车整体体积的好几分之几,还要专门插上一个显卡的话……自动驾驶汽车的画风突变了……丑出新高度……
适配过程一波三折,但幸好坚持不懈
说到实践的具体过程,老黄打开了话匣子,言情并茂地为小编描述起来!
首先一步,适配Docker。
起初老黄对此十分疑惑不解,怎么英伟达这款平台与Docker之间就这么不感冒呢?
原来NVIDIA在构建TX2内核的时候,略过了很多支持容器所必须的组件,所以解决这个问题的方法就是要重新构建这个内核,把缺失的部分补上。对此老黄做了两个部分的处理,其中一个开源项目做了一个很好的内核配置文件,另外一个项目做了很容易操作的脚本。
具体操作是这样的:
1. rebuild the TX2 kernel to suport Docker:
原生TX2不支持Docker,所以需要重新编译内核,将Docker所需的模块加载,可以参考下面两个链接来定制自己的支持Docker的内核:
https://github.com/Technica-Corporation/Tegra-Docker
https://github.com/jetsonhacks/buildJetsonTX2Kernel
最方便直接的步骤就是直接使用链接1发布的config文件,拷贝到链接2的src中,make xconfig ,然后 makeKernel.sh & copyImage.sh。
2. 在Docker内测试GPU功能。可以参考第一步的链接1.
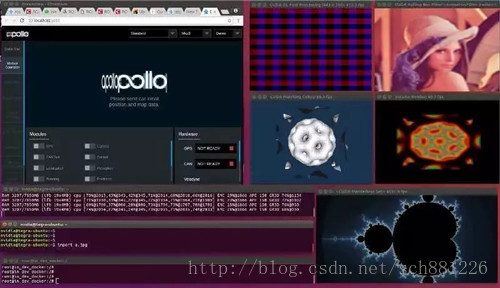
本图为在Apollo on Nvidia Tegra Tx2上开启GPU,测试几个典型CUDA应用的场景。其中开启了5个常见的CUDA应用程序,GPU利用率为20%左右。
接下来,编译Apollo!
“起初我并没有想到这个事情还挺难!”老黄强烈表示。
“这么一算,完成这个尝试总共花了3周时间。我觉得最开始研究测试Apollo各种功能的时候感觉很容易,然后就顺理成章觉得适配工作不会太难,妥妥交给一枚实习生去操作。”老黄言语中透露着轻松。
但事实上,实习生小同志辛苦适配了三天,结果……经常出现报错的警告。怎么回事儿?迅速跑到老黄这里寻找救援。
老黄叹了口气说:“发现这个事情后,我也试了几次,结果可想而知……怎么办呢?就去网络上查找相关资料,结果一看,网上救援是没可能了,存在的资料少之又少;又查了一下当时Apollo的版本,结果发现从9月27日到现在也没有最新的更新消息,没有相关指导资料的前提下,又给适配增加了难度。”
小编了解到,在适配的过程中,很多被采用的第三方工具包内部的设置并不齐备,还包括一些数据库也存在冲突,所以在编译的过程中,总会频繁出现各种各样的报错,就像我们日常安装一个软件,各种安装不上的节奏一样,老黄这才意识到当下任务的艰巨性。
深入思考之后,老黄发现了报错的本质根源,就是不兼容造成的。
他表示,针对Apollo,其实采用了大量的第三方开源工具包还有一些动态库,例如像求解,预算等,其中会涉及到一些参数设计(编译链接的时候有一个参数设计),大部分都是针对X86这个体系。如果现在要将这些放在ARM架构下的话,必须要准确的将这些参数找到并作出修正!
“但是这就存在一个问题,需要修正哪些参数我们起初是不知道的,只有在编译运行的过程中出现问题后,才能根据这个具体的问题去推测或猜测可能出现的编译参数、编译选项,然后进行修正工作,最后再来具体验证是不是能够通过,这个过程很复杂、耗时,大部分时间都是在反复尝试、反复测试。”老黄补充道。
开始这样一个纠结的过程,就需要老黄基本上从头开始按照Apollo架构体系来手工搭建运行环境以及运行体系。
所以老黄在漫长的尝试中写下了这些:
aarch64版本的Apollo需要自己配置所需的一部分依赖包,以及编译aarch64平台所需的几个第三方动态库。有兴趣的可以直接做成脚本,一键安装。
(具体涉及的相关步骤请见文后)
老黄开玩笑说:“当时一看这种情形,又回到我的老本行了,典型的软件编程工作,逐个解决问题。结果一个星期过去了,不行;两个星期过去了,还是不行……当时我也确实有那么一丝犹豫,甚至产生了动摇,想着干脆等到百度Apollo官方发出适配方案算了!”
在这个过程中,老黄也咨询了Apollo开发者社区的相关技术人员,得到的回复是,对于TX2这个版本还没有具体的适配计划,但对于1.0版本是支持的。预计到年底,会放出支持版本。当时老黄想,要等到年底,时间有点儿久。
一咬牙,老黄又投身到了解决问题的实践中!
过程艰辛不必多说,老黄给小编列举了一个让他至今印象深刻的例子,也是当时花费时间最长的一个问题。
这是一个有关数学的、线性计算数据库的问题。“到现在,那个库的名字我还记得叫qpSASES。这个库是一个开源数学计算库,既然是开源,就会涉及到编译以及编译选项的问题,进而就会和编译的静态库相关联。在X86的环境下静态库的运行和编译都没有问题,很顺畅。”老黄强调。
“但是在ARM环境下,一开始并没有报错,进库后我才发现进展又陷入了僵局!后来研究出最后的原因,这个库中的某些编译问题并不适配这个环境。如果想要解决,就必须要把这个静态库从Apollo整理好工具包中单独移出,单独手工加工下,在X86的环境下编译成动态库,才可以正常使用!
根据具体情况,老黄写下了这样的建议:
关于qpSASES。这是个数值求解库,Apollo的x86版是以依赖包的形式,aarch64是改为直接使用动态库,但是需要自己在平台下编译,否则链接报错。
a .build qpSASES to shared lib, copy it to /usr/lib
b. copy include
cp -a /apollo/third_party/qpOASES-3.2.1/include/* /usr/include/.
小编听着老黄讲述整个探索过程,感觉这项工作得以进展太不容易了!
关于这项实践的成本和后续工作
说完纠结的过程,老黄长长地出了口气,但是谈到成本,他又兴奋了起来,老黄表示整个成本真的非常低。
他说:“我们用的TX2的开发版,不到5000块钱。如果说,用它的核心版来搭建,可能还不到2000块钱,但是这个计算性能是非常强悍的。也就是说,用一个价格超过10万元的PX2能够做的事情,我们可能用到不超过4-5个这样的TX2就能达到同等效果,这样计算的话,全部配置完整也不过1万块钱左右。”
老黄强调,自己这些年做的工作,不管是哪些方面,都在不断追求一个目标:用更低成本的平台跑出更好的效果。
关于这次尝试的后续工作,老黄表示自己以及团队已经在着手跟进了,例如视觉感知,简单来说就是将基于深度学习的一个视觉感知部分加入放到TX2中。
通过性能测试来初步判断最多能够支持几个摄像机进行虚实检测。老黄对小编说:“我的计划是挂4部摄像机,这样从性能的角度,相当于TX2支持的三分之一(可以挂12部),如果可以实现4个我就非常满意了。”
另外一点,就是当时Apollo 1.5版本还没有视觉感知,所以老黄也想突击研究下这方面,如果成功的话也可以公布出去,分享给更多的开发者以及企业。
说到分享开发攻略,老黄觉得应该像Apollo学习
不得不说,Apollo开放平台的出现降低了自动驾驶的门槛,让更多企业、机构能够在一个基础平台上去做更重要的感知、决策和控制工作,而这些具体的工作被认为是自动驾驶得以进步的核心环节。对比之前,自动驾驶领域出现更多的都是“国家重大科技基金”、“国家项目支持”等这些字眼儿,一些老牌的科研单位以及高等学府才有可能直接接触这个领域。
针对技术环境与平台,老黄认为,作为开发者可以贡献一些力量帮助Apollo一起将基础工具,搭建的更多样性、更灵活、更完善。让更多相关人员在这个平台上,去做更值得做的事情。
此外,Apollo本身是一套开源系统平台,老黄觉得开发者利用开源研究以及进行业务方面的突破,得到的成果也应该开源出去,每个人都有反馈,才能让开源一直持续。
采访过程中,作为一个从业30年的程序员,老黄一直表示:“我写了三十年程序。在我的成长过程中,互联网给了太多太多的帮助,碰到问题就去网上查,已经是常态,网络上肯定有人会分享他们的调错经验。现在我把自己的一些经验、教训、经验反馈给互联网,我觉得这是特别应该做的事情。”
对此,小编很敬佩像老黄一样具有分享精神的开发者们。
关于Apollo平台,像老黄一样的开发者有话要说
回顾几个月前,Apollo 1.0还是一个不成熟、不完整,甚至可以是一个不成型的系统。短短几个月过去了,从百度公布的路线图来看,这个平台必然会倾注很多技术人员的心血去大力推广,围绕Apollo,可能会生长成为一个有规模、比较完善的生态圈。像老黄一样的开发者以及更多人都会围绕这个迅速成长的轨迹,从中获得很多帮助以及资源共享。
值得特别提及的是,Apollo针对开发者的社区会有持续不断的公开课以及社群交流,很多开发者都在分享自己在自动驾驶领域的心得。“我觉得这是一个,特别吸引我们程序员的地方,百度Apollo社群对生态的经营,十分值得赞赏。”老黄补充道。
谈及Apollo的飞速发展,就在不久前,美国的拉斯维加斯上演了一场让世界惊艳的“自动驾驶秀”,Apollo平台研发负责人王京傲借此在百度World大会上爆了个猛料,Apollo 2.0正式开放!
Apollo 2.0有什么过人之处?
据了解,Apollo 2.0已经能够实现简单的城市道路自动驾驶,包括云端服务、软件平台、参考硬件平台以及参考车辆平台在内的四大模块已全部具备。
此外为开发者带来了最完整的解决方案和灵活的架构,并首次开放安全服务,进一步强化了自定位、感知、规划决策和云端仿真等能力。
目前,Apollo 2.0版本总共有16.5万行代码。
据悉,硅谷自动驾驶创业公司AutonomouStuff在一周内将Apollo 1.0车辆升级为“Apollo 2.0版本”,实现了昼夜简单城市道路自动驾驶,充分体现Apollo 2.0的灵活性和易用性。
振奋之余,截至小编发稿前,有消息称,老黄又进一步将Apollo 2.0进行了成功的适配,真要为认真的开发者点个大大的赞!
我们有理由相信一个愿景的实现,“未来,通过Apollo平台会吸引更多新鲜力量加入进来,大家一起做好自动驾驶这项事业!”
老黄的寄语
作为开发者,我十分希望百度Apollo的开发团队能够把更多内容都填充到这个体系中,做出更多的好东西给大家用。也希望Apollo这个生态圈中,可以更加广泛地吸纳参与者、开发者,贡献自己的经验与心得,希望大家都可以共同来维护并发展这个有意义的社区生态圈。
附表:关于老黄针对这次技术适配的全面解析
【写在记录前】首先,目前适配只完成了全部模块的编译,感知部分尤其是Caffe还是只启用了CPU,在Docker里面还没有安装CUDA,随后将开始这个工作。
其次,强烈建议大家加装一块外接SSD,把Apollo部署在SSD上,以便在刷的过程中,TX2经常发生重启后桌面出不来的问题。
第三:刷机并部署完成大概要剩余5个G(要把刷内核的中间文件全部清除)。
第四:我把刷机和部署过程所需的一些依赖包的头文件以及在tx2上编译的动态库打包,大家可以直接使用,希望那个节约一些大家的时间。
最后:本人能力有限,有的地方know why,有的地方只能误打误撞know how,另外对bazel刚刚接触,很不熟练,在此抛砖引玉,请大家批评指导,谢谢!
第一部分:
- Rebuild the TX2 kernal to suport Docker :
原生TX2不支持Docker,所以需要重新编译内核,将Docker所需的模块加载,可以参考下面两个链接来定制自己的支持Docker的内核:
https://github.com/Technica-Corporation/Tegra-Docker
https://github.com/jetsonhacks/buildJetsonTX2Kernel
最方便直接的步骤就是直接使用链接1发布的config文件,拷贝到链接2的SRC中,make xconfig ,然后 makeKernal.sh & copyImage.sh。
- 在Docker内测试GPU功能。可以参考第一步的链接1.
第二部分:编译Apollo
aarch64版本的Apollo需要自己配置所需的一部分依赖包,以及编译aarch64平台所需的几个第三方动态库。有兴趣的可以直接做成脚本,一键安装。
具体清单如下:
- caffe
aarch64版本需要自己准备caffe的依赖包,为了方便直接模仿x86版本,在external目录下手工添加@caffe and caffe dir。
另外我下载的caffe版本可能比较老,使用的是2.6版的protobuf,所以要使用protobuf3.3版重新生成一下caffe.pb.h。具体步骤如下:
a. install the bazel package to external:@caffe and caffe dir,copy from x86 apollo
cd /root/.cache/bazel/_bazel_root/540135163923dd7d5820f3ee4b306b32/external/
b.copy caffe include to:/usr/include/caffe, and regenerate caffe.pb.h,using protoc 3.3.0
cp -a /media/nvidia/ssd/install_apollo/caffe_package/caffe_external/. /usr/include/caffe/.
c.lib
cp -a /media/nvidia/ssd/install_apollo/caffe_package/lib/* /usr/lib/.
- qpSASES
这是个数值求解库,Apollo的x86版是以依赖包的形式,aarch64是改为直接使用动态库,但是需要自己在平台下编译,否则链接报错。
a .build qpSASES to shared lib, copy it to /usr/lib
b. copy include
cp -a /apollo/third_party/qpOASES-3.2.1/include/* /usr/include/.
- Ipopt 这个需要一系列的库,要在TX2上编译,其他平台编译的也不行。
1.include
cp -a /media/nvidia/ssd/install_apollo/IPopt/include/coin/* /usr/include/.
cp -a /media/nvidia/ssd/install_apollo/IPopt/include/LinAlg/* /usr/include/.
cp -a /media/nvidia/ssd/install_apollo/IPopt/include/Interfaces/* /usr/include/.
2.lib—–Ipopt的几个目录的库都要拷贝过去,
cp -a /media/nvidia/ssd/install_apollo/IPopt/lib/* /usr/lib/.
cp …
cp …
- ros
需要自己准备aarch64版本的ros。
(1)准备include
cp -a /media/nvidia/ssd/install_apollo/ros/include/* /usr/include/.
(2)将ros目录拷贝至 /home/tmp/ros
- gflags
WORKSPASE指定的依赖包里面有gflags,但编译时候还是需要手工准备头文件和库文件,直接拷过去。
(1)include
cp -a /media/nvidia/ssd/install_apollo/gflags/include/* /usr/include/.
(2)lib
cp -a /media/nvidia/ssd/install_apollo/gflags/lib/* /usr/lib/.
- glog
同上,直接安装。
apt-get install libgoogle-glog-dev
- Build —- 经过以上步骤,应该可以编译通过,感知模块也可以通过。
【相关报告问题】
报告问题之一:
Apolloauto的Github提供了aarch64的ros版本是1.51,可以直接下载release使用,我尝试了一下自己编译,发现少了个rosbag指令。使用release版的话,rosbag的play指令报错,导致现在无法在TX2上回放数据。
报告问题之二:
在Build时,全部通过OK,但是在bazel-bin下并没有生成target,最后是使用Bazel Build 对modules下的模块进行手工编译。
报告问题之三:
gflag, glog,gtest是出问题最多的地方,有的地方使用bazel构建包生成的库,有的第三方依赖使用自带的库,兼容性的问题一直存在。所有使用gmock的地方我始终没有解决,所以 临时屏蔽了几个单元测试。
写在最后
按照开发者提供的运行文档,Apollo团队也用相同套件编译安装实践了一遍,并整理了若干兼容细节,形成了官方支持TX2,CPU为ARM平台的支持文档。
目前发现Apollo部分模块对于ARM架构的计算单元兼容性支持还不够好,如感知红绿灯识别模块、定位模块,在编译安装的过程,先跳过该模块编译部分,已与研发团队沟通,后续会输出完整的文档分享。